
1. Overview
I recently installed PyCharm on Windows 11 and debugged and ran Ultralytics YOLO as described here. I ran the program on a laptop LIFEBOOK WU2/D2, which does not have a GPU.
This time, I ran it on an ESPRIMO WD2/H2 desktop computer with an NVIDIA GeForce GTX 1650 (GPGPU).
The specifications of the desktop computers used are listed in the table at the end of this page.
I also installed the Linux version of PyCharm on Ubuntu/WSL2 and compared the run time of the Ultralytics training with that of the Windows version running on a GPU.
2. Running in a GPU-based environment
2.1. Creating a new PyCharm Project
A new PyCharm Project has been created with default settings.
2.2. Installing PyTorch for CUDA
On this PyTorch page, I selected the conditions under which I would like to install PyTorch, as shown in the example image below. Since CUDA Toolkit 12.4 was already installed on my Windows 11 desktop computer, I made the selection shown in the example image below.

I copied the following command from the Run this Command: field in the image above to the PyCharm terminal and executed it.
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
The image below shows the screen shot when the above command is pasted and executed in the PyCharm terminal.
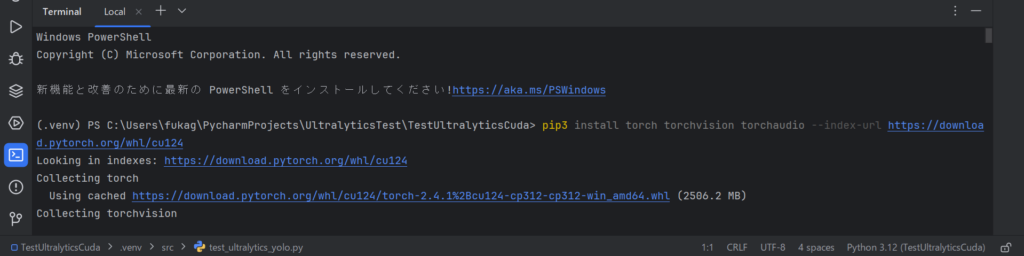
The following log was output. The CUDA version of PyTorch was installed from PowerShell on Windows 11 using the pip3 command.
(.venv) PS C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda> pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124 Looking in indexes: https://download.pytorch.org/whl/cu124 Collecting torch Using cached https://download.pytorch.org/whl/cu124/torch-2.4.1%2Bcu124-cp312-cp312-win_amd64.whl (2506.2 MB) Collecting torchvision Using cached https://download.pytorch.org/whl/cu124/torchvision-0.19.1%2Bcu124-cp312-cp312-win_amd64.whl (5.9 MB) ... Installing collected packages: mpmath, typing-extensions, sympy, setuptools, pillow, numpy, networkx, MarkupSafe, fsspec, filelock, jinja2, torch, torchvision, torchaudio Successfully installed MarkupSafe-2.1.5 filelock-3.13.1 fsspec-2024.2.0 jinja2-3.1.3 mpmath-1.3.0 networkx-3.2.1 numpy-1.26.3 pillow-10.2.0 setuptools-70.0.0 sympy-1.12 torch-2.4.1+cu124 torchaudio-2.4.1+cu124 torchvision-0.19.1+cu124 typing-extensions-4.9.0
2.3. Installing Ultralytics
I installed Ultralytics in editable mode, following the Git clone installation instructions on the Ultralytics page.
The following commands were entered in sequence on PyCharm’s PowerShell terminal.
(.venv) PS C:\...\TestUltralyticsCuda> cd .venv (.venv) PS C:\...\TestUltralyticsCuda\.venv> mkdir src (.venv) PS C:\...\TestUltralyticsCuda\.venv> cd src (.venv) PS C:\...\TestUltralyticsCuda\.venv\src> git clone https://github.com/ultralytics/ultralytics (.venv) PS C:\...\TestUltralyticsCuda\.venv\src> cd .\ultralytics\ (.venv) PS C:\...\TestUltralyticsCuda\.venv\src\ultralytics> pip install -e .
After that, I added the Ultralytics path to Project’s Interpreter Paths, as described in Section 3.4, “Adding the Ultralytics Path” on this page.
2.4. Running Ultralytics
2.4.1. Check GPU
I ran the Python script check_ultralytics.py with the following contents.
import ultralytics ultralytics.checks()
The following log is output to the PyCharm console, confirming that the program runs using an NVIDIA GeForce GTX 1650 (GPGPU).
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\check_ultralytics.py Ultralytics 8.3.7 🚀 Python-3.12.3 torch-2.4.1+cu124 CUDA:0 (NVIDIA GeForce GTX 1650, 4096MiB) Setup complete ✅ (16 CPUs, 15.2 GB RAM, 260.6/1903.6 GB disk) Process finished with exit code 0
2.4.2. Run object detection
I ran the Python script test_ultralytics_yolo.py with the following contents.
from ultralytics import YOLO
if __name__ == '__main__':
# Load a pretrained YOLOv8n model
model = YOLO("yolo11n.pt")
# Define remote image or video URL
source = "https://www.leafwindow.com/wordpress-05/wp-content/uploads/2023/03/DSC00283-min-SonyAlpha-%E6%A8%AA.jpg"
# Run inference on the source
results = model(source) # list of Results objects
# Save image
results[0].save("A_bird_taken_at_nagara_park.jpg")
The following log was output to the console. The inference took 24.3 ms.
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\test_ultralytics_yolo.py Found https://www.leafwindow.com/wordpress-05/wp-content/uploads/2023/03/DSC00283-min-SonyAlpha-横.jpg locally at DSC00283-min-SonyAlpha-横.jpg image 1/1 C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\DSC00283-min-SonyAlpha-横.jpg: 448x640 1 bird, 24.3ms Speed: 1.1ms preprocess, 24.3ms inference, 59.9ms postprocess per image at shape (1, 3, 448, 640) Process finished with exit code 0
2.4.3. Run training
The Python script test_ultralytics_yolo_train.py with the following content was executed.
I specified data=“coco128.yaml” and ran training on a dataset of 128 images for object detection.
I specified epochs=100 to run 100 epochs of training with 128 images.
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="coco128.yaml", epochs=100, imgsz=640, amp=False, half=False)
The following log was output to the console. 100 epochs of training took 0.590 hours (35.4 minutes).
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\test_ultralytics_yolo_train.py
Ultralytics 8.3.7 🚀 Python-3.12.3 torch-2.4.1+cu124 CUDA:0 (NVIDIA GeForce GTX 1650, 4096MiB)
engine\trainer: task=detect, mode=train, model=yolo11n.pt, data=coco128.yaml, epochs=100, time=None, patience=100, batch=16, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train28, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=False, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\ultralytics\runs\detect\train28
...
Starting training for 100 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/100 4.82G 1.221 1.583 1.271 217 640: 100%|██████████| 8/8 [00:17<00:00, 2.20s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:10<00:00, 2.70s/it]
all 128 929 0.664 0.593 0.676 0.507
...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
100/100 4.67G 0.7988 0.6416 0.9954 75 640: 100%|██████████| 8/8 [00:11<00:00, 1.39s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:08<00:00, 2.04s/it]
all 128 929 0.824 0.831 0.882 0.732
100 epochs completed in 0.590 hours.
...
2.4.4. Execute training process with different Batch Sizes depending on the GPU memory size
The training was performed by adding batch=-1 to the parameter of the model.train(…) method as shown below. The default Batch Size for training is 16, as described on this page, but the Batch Size for efficient training is hardware-dependent. If the parameter batch=-1 is specified, training will be run with a batch size that results in approximately 60% GPU memory usage.
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="coco128.yaml", epochs=100, imgsz=640, batch=-1, amp=False, half=False)
When the above Python script was executed, the following log was output to the console. 100 epochs of training took 0.162 hours (9.72 minutes).
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\test_ultralytics_yolo_train.py
New https://pypi.org/project/ultralytics/8.3.10 available 😃 Update with 'pip install -U ultralytics'
Ultralytics 8.3.7 🚀 Python-3.12.3 torch-2.4.1+cu124 CUDA:0 (NVIDIA GeForce GTX 1650, 4096MiB)
engine\trainer: task=detect, mode=train, model=yolo11n.pt, data=coco128.yaml, epochs=100, time=None, patience=100, batch=-1, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train34, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=False, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\ultralytics\runs\detect\train34
...
AutoBatch: Using batch-size 7 for CUDA:0 2.15G/4.00G (54%) ✅
...
Starting training for 100 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/100 2.23G 1.155 1.687 1.255 21 640: 100%|██████████| 19/19 [00:04<00:00, 3.84it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:01<00:00, 6.11it/s]
all 128 929 0.668 0.6 0.675 0.502
...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
100/100 2.17G 0.8717 0.7377 1.018 15 640: 100%|██████████| 19/19 [00:03<00:00, 4.76it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:01<00:00, 7.93it/s]
all 128 929 0.812 0.826 0.873 0.711
100 epochs completed in 0.162 hours.
...
When using CUDA on Windows 11 and executing the model.train(…) method as in the Ultralytics sample Python script, an error similar to the one on this page occurred, so I called the method model.train(…) from if __name__ == ‘__main__’:.
Note 2:
When executing the model.train(…) method on Windows 11 with NVIDIA GeForce GTX 1650, an error similar to the one on this page occurred during validation, so I added amp=False and half=False to the method model.train(…).
Note 3:
The training time was 0.163 hours when batch=0.7 was specified and the training time was more than 0.2 hours when batch=0.9 was specified.
3. Running on CPU only
To compare the execution times when using a GPU and when running only on a CPU, I ran the Python scripts in 2.4.2. and 2.4.3. above on the same desktop computer using only CPU.
3.1. Create a Project with settings to use CPU only
As in 2.1. above, a new PyCharm Project was created with default settings. I then skipped the “Installing PyTorch for CUDA” step in section 2.2. above and installed Ultralytics following the “Installing Ultralytics” step in section 2.3. above.
After following the above steps, I installed PyCharm’s Project, which runs Ultralytics on CPU only.
3.2. Running Ultralytics
3.2.1. Check that only CPU is used
The same Python script check_ultralytics.py as in 2.4.1. above was executed.
The following log is output to the PyCharm console, confirming that the program is executed only on CPU.
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\src\check_ultralytics.py Ultralytics 8.3.7 🚀 Python-3.12.3 torch-2.4.1+cpu CPU (13th Gen Intel Core(TM) i5-13400) Setup complete ✅ (16 CPUs, 15.2 GB RAM, 262.5/1903.6 GB disk) Process finished with exit code 0
3.2.2. Performs object detection inference only on CPU
The same Python script test_ultralytics_yolo.py as in 2.4.2. above was executed.
The following log was output to the console. The inference took 108.6 ms.
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\src\test_ultralytics_yolo.py Found https://www.leafwindow.com/wordpress-05/wp-content/uploads/2023/03/DSC00283-min-SonyAlpha-横.jpg locally at DSC00283-min-SonyAlpha-横.jpg image 1/1 C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\src\DSC00283-min-SonyAlpha-横.jpg: 448x640 1 bird, 108.6ms Speed: 6.1ms preprocess, 108.6ms inference, 7.1ms postprocess per image at shape (1, 3, 448, 640) Process finished with exit code 0
3.2.3. Performs object detection training on CPU only
The same Python script test_ultralytics_yolo_train.py as in 2.4.3. above was run.
The following logs were output to the console. Training took 1.007 hours (60.42 minutes).
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\src\test_ultralytics_yolo_train.py
New https://pypi.org/project/ultralytics/8.3.9 available 😃 Update with 'pip install -U ultralytics'
Ultralytics 8.3.7 🚀 Python-3.12.3 torch-2.4.1+cpu CPU (13th Gen Intel Core(TM) i5-13400)
engine\trainer: task=detect, mode=train, model=yolo11n.pt, data=coco128.yaml, epochs=100, time=None, patience=100, batch=16, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train33, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=False, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\ultralytics\runs\detect\train33
...
Starting training for 100 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/100 0G 1.164 1.332 1.256 278 640: 100%|██████████| 8/8 [00:28<00:00, 3.61s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:10<00:00, 2.50s/it]
all 128 929 0.687 0.595 0.68 0.513
...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
100/100 0G 0.8197 0.637 0.9913 126 640: 100%|██████████| 8/8 [00:25<00:00, 3.25s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:09<00:00, 2.41s/it]
all 128 929 0.893 0.813 0.886 0.739
100 epochs completed in 1.007 hours.
...
3.2.4. Run training on CPU only with batch=-1
As in 2.4.4. above, batch=-1 was specified and training was performed on CPU only.
As shown below, a log was output indicating that proper Batch Size estimation was not performed for CPU-only runs, and the default Batch Size of 16 was applied.
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\src\test_ultralytics_yolo_train.py New https://pypi.org/project/ultralytics/8.3.10 available 😃 Update with 'pip install -U ultralytics' Ultralytics 8.3.7 🚀 Python-3.12.3 torch-2.4.1+cpu CPU (13th Gen Intel Core(TM) i5-13400) engine\trainer: task=detect, mode=train, model=yolo11n.pt, data=coco128.yaml, epochs=100, time=None, patience=100, batch=-1, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train39, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=False, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\ultralytics\runs\detect\train39 ... AutoBatch: Computing optimal batch size for imgsz=640 at 60.0% CUDA memory utilization. AutoBatch: ⚠️ intended for CUDA devices, using default batch-size 16 ...
3.2.5. Run training on CPU only with batch=7
When batch=-1 was specified in 2.4.4. above, training was executed with Batch Size 7.
For comparison, training was run on CPU only, specifying a batch size of batch=7.
As shown in the log below, training took 0.911 hours (54.66 minutes).
The processing time is about 5.6 times longer than the processing time of 0.162 in 2.4.4. using a GPU.
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\src\test_ultralytics_yolo_train.py
New https://pypi.org/project/ultralytics/8.3.10 available 😃 Update with 'pip install -U ultralytics'
Ultralytics 8.3.7 🚀 Python-3.12.3 torch-2.4.1+cpu CPU (13th Gen Intel Core(TM) i5-13400)
engine\trainer: task=detect, mode=train, model=yolo11n.pt, data=coco128.yaml, epochs=100, time=None, patience=100, batch=7, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train40, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=False, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\ultralytics\runs\detect\train40
...
Starting training for 100 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/100 0G 1.166 1.45 1.241 41 640: 100%|██████████| 19/19 [00:27<00:00, 1.44s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:08<00:00, 1.21it/s]
all 128 929 0.681 0.6 0.677 0.508
...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
100/100 0G 0.8943 0.75 1.037 7 640: 100%|██████████| 19/19 [00:23<00:00, 1.26s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:07<00:00, 1.26it/s]
all 128 929 0.842 0.811 0.87 0.707
100 epochs completed in 0.911 hours.
...
4. Comparison of execution time with training using GPU on WSL2
4.1. Installing PyCharm on Ubuntu/WSL2
I downloaded the Linux version of PyCharm Community Edition from this page. After downloading, I extracted PyCharm to the /opt/ directory using the following command.
sudo tar xzf pycharm-*.tar.gz -C /opt/
I have rewritten the permissions of the directory so that I can upgrade PyCharm with the permissions of my user account.
sudo chown -R fukagai.fukagai /opt/pycharm-community-2024.2.2/
The following command will start the Linux version of PyCharm. No X server settings were made. The application was started as a GUI application using WSLg.
/opt/pycharm-community-2024.2.2/bin/pycharm &
4.2. Installing Ultralytics
After creating a PyCharm Project with the default settings, I entered the following commands on the PyCharm terminal. Ultralytics is installed in editable mode. The following command installed Ultralytics with a GPU-enabled configuration.
(.venv) fukagai@ESPRIMOWD2H2:~/PycharmProjects/TestUltralyticsCuda/.venv$ mkdir src (.venv) fukagai@ESPRIMOWD2H2:~/PycharmProjects/TestUltralyticsCuda/.venv$ cd src/ (.venv) fukagai@ESPRIMOWD2H2:~/PycharmProjects/TestUltralyticsCuda/.venv/src$ git clone https://github.com/ultralytics/ultralytics (.venv) fukagai@ESPRIMOWD2H2:~/PycharmProjects/TestUltralyticsCuda/.venv/src$ cd ultralytics/ (.venv) fukagai@ESPRIMOWD2H2:~/PycharmProjects/TestUltralyticsCuda/.venv/src/ultralytics$ pip install -e . Obtaining file:///home/fukagai/PycharmProjects/TestUltralyticsCuda/.venv/src/ultralytics Installing build dependencies ... done Checking if build backend supports build_editable ... done Getting requirements to build editable ... done Preparing editable metadata (pyproject.toml) ... done ... Successfully installed MarkupSafe-3.0.1 certifi-2024.8.30 charset-normalizer-3.4.0 contourpy-1.3.0 cycler-0.12.1 filelock-3.16.1 fonttools-4.54.1 fsspec-2024.9.0 idna-3.10 jinja2-3.1.4 kiwisolver-1.4.7 matplotlib-3.9.2 mpmath-1.3.0 networkx-3.4.1 numpy-2.1.2 nvidia-cublas-cu12-12.1.3.1 nvidia-cuda-cupti-cu12-12.1.105 nvidia-cuda-nvrtc-cu12-12.1.105 nvidia-cuda-runtime-cu12-12.1.105 nvidia-cudnn-cu12-9.1.0.70 nvidia-cufft-cu12-11.0.2.54 nvidia-curand-cu12-10.3.2.106 nvidia-cusolver-cu12-11.4.5.107 nvidia-cusparse-cu12-12.1.0.106 nvidia-nccl-cu12-2.20.5 nvidia-nvjitlink-cu12-12.6.77 nvidia-nvtx-cu12-12.1.105 opencv-python-4.10.0.84 packaging-24.1 pandas-2.2.3 pillow-10.4.0 psutil-6.0.0 py-cpuinfo-9.0.0 pyparsing-3.1.4 python-dateutil-2.9.0.post0 pytz-2024.2 pyyaml-6.0.2 requests-2.32.3 scipy-1.14.1 seaborn-0.13.2 six-1.16.0 sympy-1.13.3 torch-2.4.1 torchvision-0.19.1 tqdm-4.66.5 triton-3.0.0 typing-extensions-4.12.2 tzdata-2024.2 ultralytics-8.3.11 ultralytics-thop-2.0.9 urllib3-2.2.3
After installation, as with PyCharm for Windows, I added the Ultralytics path to Project’s Interpreter Paths, as described in Section 3.4, “Adding the Ultralytics Path” on this page.
4.3. Run Ultralytics training
As in 2.4.4. above, I specified batch=-1 and ran the Ultralytics training on Ubuntu with WSL2.
The following Python script, identical to 2.4.4. above, was executed.
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="coco128.yaml", epochs=100, imgsz=640, batch=-1, amp=False, half=False)
The following log is output to the PyCharm console: 100 epochs of training have been completed in 0.168 hours. The execution time was close to the time when run on the Windows version using the GPU.
/home/fukagai/PycharmProjects/TestUltralyticsCuda/.venv/bin/python /home/fukagai/PycharmProjects/TestUltralyticsCuda/.venv/src/test_ultralytics_train.py
...
Ultralytics 8.3.11 🚀 Python-3.10.12 torch-2.4.1+cu121 CUDA:0 (NVIDIA GeForce GTX 1650, 4096MiB)
engine/trainer: task=detect, mode=train, model=yolo11n.pt, data=coco128.yaml, epochs=100, time=None, patience=100, batch=-1, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=False, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=/home/fukagai/PycharmProjects/TestUltralyticsCuda/.venv/src/ultralytics/runs/detect/train
...
AutoBatch: Computing optimal batch size for imgsz=640 at 60.0% CUDA memory utilization.
AutoBatch: CUDA:0 (NVIDIA GeForce GTX 1650) 4.00G total, 0.04G reserved, 0.02G allocated, 3.94G free
...
Starting training for 100 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/100 2.23G 1.155 1.687 1.255 21 640: 100%|██████████| 19/19 [00:05<00:00, 3.38it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:02<00:00, 4.24it/s]
all 128 929 0.669 0.592 0.673 0.5
...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
100/100 2.17G 0.8802 0.744 1.02 15 640: 100%|██████████| 19/19 [00:04<00:00, 4.62it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:01<00:00, 6.70it/s]
all 128 929 0.818 0.828 0.875 0.713
100 epochs completed in 0.168 hours.
...