
1. 概要
先日、こちらのページに記載したように、Windows 11 に PyCharm をインストールし、Ultralytics YOLO をデバッグ実行しました。その際、GPU を搭載していないノートパソコン LIFEBOOK WU2/D2 で実行しました。
今回は、NVIDIA GeForce GTX 1650 (GPGPU) をセットしたデスクトップパソコン ESPRIMO WD2/H2 で実行しました。使用したデスクトップパソコンのスペックはこちらのページの末尾の表に記載しました。
また、WSL2 上の Ubuntu に PyCharm の Linux 版をインストールし、Ultralytics の training の実行時間を Windows 版で GPU を使用して実行した場合と比較しました。
2. GPU を使用した環境での実行
2.1. 新しい PyCharm の Project の作成
新しい PyCharm の Project をデフォルトの設定で作成しました。
2.2. CUDA 版 PyTorch のインストール
こちらの PyTorch のページで下の画像の例のように PyTorch をインストールする条件を選択しました。私の Windows 11 のデスクトップパソコンには、CUDA Toolkit 12.4 がすでにインストールされていたため、下の画像の例のような選択をしました。

上の画像の Run this Command: の欄の下記のコマンドを PyCharm のターミナルにコピーして実行しました。
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
下の画像は PyCharm 下段のターミナルに上記のコマンドを貼り付けて実行したときの画面です。
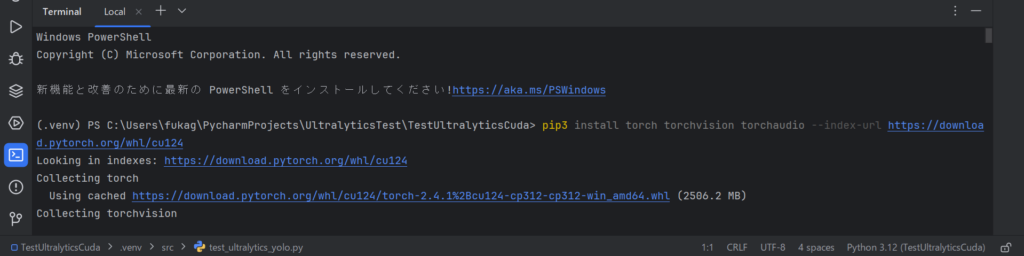
下記のようなログが出力されました。Windows 11 の PowerShell から pip3 コマンドで CUDA 版の PyTorch をインストールしています。
(.venv) PS C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda> pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124 Looking in indexes: https://download.pytorch.org/whl/cu124 Collecting torch Using cached https://download.pytorch.org/whl/cu124/torch-2.4.1%2Bcu124-cp312-cp312-win_amd64.whl (2506.2 MB) Collecting torchvision Using cached https://download.pytorch.org/whl/cu124/torchvision-0.19.1%2Bcu124-cp312-cp312-win_amd64.whl (5.9 MB) ... Installing collected packages: mpmath, typing-extensions, sympy, setuptools, pillow, numpy, networkx, MarkupSafe, fsspec, filelock, jinja2, torch, torchvision, torchaudio Successfully installed MarkupSafe-2.1.5 filelock-3.13.1 fsspec-2024.2.0 jinja2-3.1.3 mpmath-1.3.0 networkx-3.2.1 numpy-1.26.3 pillow-10.2.0 setuptools-70.0.0 sympy-1.12 torch-2.4.1+cu124 torchaudio-2.4.1+cu124 torchvision-0.19.1+cu124 typing-extensions-4.9.0
2.3. Ultralytics のインストール
こちらの Ultralytics のページの Git clone によるインストール手順にしたがい、Ultralytics を editable mode でインストールしました。
PyCharm の PowerShell のターミナルに下記のようなコマンドを順に入力しました。
(.venv) PS C:\...\TestUltralyticsCuda> cd .venv (.venv) PS C:\...\TestUltralyticsCuda\.venv> mkdir src (.venv) PS C:\...\TestUltralyticsCuda\.venv> cd src (.venv) PS C:\...\TestUltralyticsCuda\.venv\src> git clone https://github.com/ultralytics/ultralytics (.venv) PS C:\...\TestUltralyticsCuda\.venv\src> cd .\ultralytics\ (.venv) PS C:\...\TestUltralyticsCuda\.venv\src\ultralytics> pip install -e .
その後、こちらのページの「3.4. Ultralytics のパスの追加」の手順で Git clone した Ultralytics のパスを Project の Interpreter Paths に追加しました。
2.4. Ultralytics の実行
2.4.1. GPU使用の確認
下記の内容の Python スクリプト check_ultralytics.py を実行しました。
import ultralytics ultralytics.checks()
PyCharm 下段のコンソールに下記のようなログが出力され、NVIDIA GeForce GTX 1650 (GPGPU) を使ってプログラムが実行されることを確認しました。
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\check_ultralytics.py Ultralytics 8.3.7 🚀 Python-3.12.3 torch-2.4.1+cu124 CUDA:0 (NVIDIA GeForce GTX 1650, 4096MiB) Setup complete ✅ (16 CPUs, 15.2 GB RAM, 260.6/1903.6 GB disk) Process finished with exit code 0
2.4.2. 物体検出の実行
下記の内容の Python スクリプト test_ultralytics_yolo.py を実行しました。
from ultralytics import YOLO
if __name__ == '__main__':
# Load a pretrained YOLOv8n model
model = YOLO("yolo11n.pt")
# Define remote image or video URL
source = "https://www.leafwindow.com/wordpress-05/wp-content/uploads/2023/03/DSC00283-min-SonyAlpha-%E6%A8%AA.jpg"
# Run inference on the source
results = model(source) # list of Results objects
# Save image
results[0].save("A_bird_taken_at_nagara_park.jpg")
コンソールには下記のようなログが出力されました。推定処理 (inference) には 24.3 ms 要しました。
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\test_ultralytics_yolo.py Found https://www.leafwindow.com/wordpress-05/wp-content/uploads/2023/03/DSC00283-min-SonyAlpha-横.jpg locally at DSC00283-min-SonyAlpha-横.jpg image 1/1 C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\DSC00283-min-SonyAlpha-横.jpg: 448x640 1 bird, 24.3ms Speed: 1.1ms preprocess, 24.3ms inference, 59.9ms postprocess per image at shape (1, 3, 448, 640) Process finished with exit code 0
2.4.3. training 処理の実行
下記の内容の Python スクリプト test_ultralytics_yolo_train.py を実行しました。
data=”coco128.yaml” を指定し、128枚の物体検出用のデータセットで training を実行しました。
epochs=100 を指定し、128枚の画像で100回の training を実行しています。
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="coco128.yaml", epochs=100, imgsz=640, amp=False, half=False)
コンソールには下記のようなログが出力されました。100 epoch の training に 0.590 時間 (35.4分) 要しました。
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\test_ultralytics_yolo_train.py
Ultralytics 8.3.7 🚀 Python-3.12.3 torch-2.4.1+cu124 CUDA:0 (NVIDIA GeForce GTX 1650, 4096MiB)
engine\trainer: task=detect, mode=train, model=yolo11n.pt, data=coco128.yaml, epochs=100, time=None, patience=100, batch=16, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train28, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=False, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\ultralytics\runs\detect\train28
...
Starting training for 100 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/100 4.82G 1.221 1.583 1.271 217 640: 100%|██████████| 8/8 [00:17<00:00, 2.20s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:10<00:00, 2.70s/it]
all 128 929 0.664 0.593 0.676 0.507
...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
100/100 4.67G 0.7988 0.6416 0.9954 75 640: 100%|██████████| 8/8 [00:11<00:00, 1.39s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:08<00:00, 2.04s/it]
all 128 929 0.824 0.831 0.882 0.732
100 epochs completed in 0.590 hours.
...
2.4.4. GPU メモリのサイズに応じて Batch Size を変えた training 処理の実行
上記 2.4.3. の Python スクリプト test_ultralytics_yolo_train.py の model.train(…) メソッドのパラメータに下記のように batch=-1 を追加して training を実行しました。こちらのページに記載されているように training の Batch Size のデフォルト値は 16 ですが、training を効率的に実行するための Batch Size はハードウェアに依存します。パラメータ batch=-1 を指定すると GPU メモリの使用率が約 60 % となるような Batch Size で training が実行されます。
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="coco128.yaml", epochs=100, imgsz=640, batch=-1, amp=False, half=False)
上記の Python スクリプトを実行すると、コンソールには下記のようなログが出力されました。100 epoch の training に 0.162 時間 (9.72分) 要しました。
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\test_ultralytics_yolo_train.py
New https://pypi.org/project/ultralytics/8.3.10 available 😃 Update with 'pip install -U ultralytics'
Ultralytics 8.3.7 🚀 Python-3.12.3 torch-2.4.1+cu124 CUDA:0 (NVIDIA GeForce GTX 1650, 4096MiB)
engine\trainer: task=detect, mode=train, model=yolo11n.pt, data=coco128.yaml, epochs=100, time=None, patience=100, batch=-1, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train34, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=False, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\ultralytics\runs\detect\train34
...
AutoBatch: Using batch-size 7 for CUDA:0 2.15G/4.00G (54%) ✅
...
Starting training for 100 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/100 2.23G 1.155 1.687 1.255 21 640: 100%|██████████| 19/19 [00:04<00:00, 3.84it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:01<00:00, 6.11it/s]
all 128 929 0.668 0.6 0.675 0.502
...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
100/100 2.17G 0.8717 0.7377 1.018 15 640: 100%|██████████| 19/19 [00:03<00:00, 4.76it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:01<00:00, 7.93it/s]
all 128 929 0.812 0.826 0.873 0.711
100 epochs completed in 0.162 hours.
...
Windows 11 上で CUDA を使用し、Ultralytics のサンプル Python スクリプトと同じように model.train(…) メソッドを実行すると、こちらのページと同様のエラーが発生したため、if __name__ == ‘__main__’: から model.train(…) メソッドを実行するようにしました。
補足2:
Windows 11 上で NVIDIA GeForce GTX 1650 を使用して model.train(…) メソッドを実行すると、こちらのページと同様のエラーが validation 実行時に発生したため、amp=False, half=False を model.train(…) メソッドのパラメータに追加しました。
補足3:
こちらのページに記載された GPU メモリの使用率を指定する方法で batch=0.7 を指定した際の training 時間は 0.163 時間、 batch=0.8 を指定した際の training 時間は 0.164 時間、batch=0.9 を指定した際の training 時間は 0.2 時間以上になりました。
3. CPU のみでの実行
GPU を使用したときと CPU のみで実行したときの実行時間を比較するため、同じデスクトップパソコン上で、CPU のみを使用する条件で上記 2.4.2. と 2.4.3. の Python スクリプトを実行しました。
3.1. CPU のみを利用する設定で Project を作成
上記 2.1. と同様、新しい PyCharm の Project をデフォルトの設定で作成しました。その後、上記 2.2. の「CUDA 版 PyTorch のインストール」の手順をスキップし、上記 2.3. の「Ultralytics のインストール」の手順で Ultralytics をインストールしました。
上記の手順でインストールしたところ、CPU のみで Ultralytics を実行する PyCharm の Project になりました。
3.2. Ultralytics の実行
3.2.1. CPUのみが使用されることの確認
上記 2.4.1. と同じ Python スクリプト check_ultralytics.py を実行しました。
PyCharm 下段のコンソールに下記のようなログが出力され、CPU のみでプログラムが実行されることを確認しました。
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\src\check_ultralytics.py Ultralytics 8.3.7 🚀 Python-3.12.3 torch-2.4.1+cpu CPU (13th Gen Intel Core(TM) i5-13400) Setup complete ✅ (16 CPUs, 15.2 GB RAM, 262.5/1903.6 GB disk) Process finished with exit code 0
3.2.2. CPU のみで物体検出の推定処理 (inference) を実行
上記 2.4.2. と同じ Python スクリプト test_ultralytics_yolo.py を実行しました。
コンソールには下記のようなログが出力されました。推定処理 (inference) には 108.6 ms 要しました。
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\src\test_ultralytics_yolo.py Found https://www.leafwindow.com/wordpress-05/wp-content/uploads/2023/03/DSC00283-min-SonyAlpha-横.jpg locally at DSC00283-min-SonyAlpha-横.jpg image 1/1 C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\src\DSC00283-min-SonyAlpha-横.jpg: 448x640 1 bird, 108.6ms Speed: 6.1ms preprocess, 108.6ms inference, 7.1ms postprocess per image at shape (1, 3, 448, 640) Process finished with exit code 0
3.2.3. CPU のみで物体検出の学習処理 (training) を実行
上記 2.4.3. と同じ Python スクリプト test_ultralytics_yolo_train.py を実行しました。
コンソールには下記のようなログが出力されました。学習処理 (training) には 1.007 時間 (60.42 分) 要しました。
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\src\test_ultralytics_yolo_train.py
New https://pypi.org/project/ultralytics/8.3.9 available 😃 Update with 'pip install -U ultralytics'
Ultralytics 8.3.7 🚀 Python-3.12.3 torch-2.4.1+cpu CPU (13th Gen Intel Core(TM) i5-13400)
engine\trainer: task=detect, mode=train, model=yolo11n.pt, data=coco128.yaml, epochs=100, time=None, patience=100, batch=16, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train33, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=False, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\ultralytics\runs\detect\train33
...
Starting training for 100 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/100 0G 1.164 1.332 1.256 278 640: 100%|██████████| 8/8 [00:28<00:00, 3.61s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:10<00:00, 2.50s/it]
all 128 929 0.687 0.595 0.68 0.513
...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
100/100 0G 0.8197 0.637 0.9913 126 640: 100%|██████████| 8/8 [00:25<00:00, 3.25s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:09<00:00, 2.41s/it]
all 128 929 0.893 0.813 0.886 0.739
100 epochs completed in 1.007 hours.
...
3.2.4. CPU のみで batch=-1 を指定して training を実行
上記 2.4.4. と同様、batch=-1 を指定し、CPU のみで training を実行しました。
下記のように CPU のみの実行では適切な Batch Size の推定が実施されないことを示すログが出力され、デフォルトの Batch Size 16 が適用されました。
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\src\test_ultralytics_yolo_train.py New https://pypi.org/project/ultralytics/8.3.10 available 😃 Update with 'pip install -U ultralytics' Ultralytics 8.3.7 🚀 Python-3.12.3 torch-2.4.1+cpu CPU (13th Gen Intel Core(TM) i5-13400) engine\trainer: task=detect, mode=train, model=yolo11n.pt, data=coco128.yaml, epochs=100, time=None, patience=100, batch=-1, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train39, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=False, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\ultralytics\runs\detect\train39 ... AutoBatch: Computing optimal batch size for imgsz=640 at 60.0% CUDA memory utilization. AutoBatch: ⚠️ intended for CUDA devices, using default batch-size 16 ...
3.2.5. CPU のみで batch=7 を指定して training を実行
上記 2.4.4. で batch=-1 を指定した際、Batch Size 7 で training が実行されました。
比較のため、batch=7 のように Batch Size を指定して CPU のみで training を実行しました。
下記のログのように training には 0.911 時間 (54.66分) 要しました。
GPU を使用した 2.4.4. の処理時間 0.162 の約 5.6 倍の処理時間になります。
C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\Scripts\python.exe C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCpu\.venv\src\test_ultralytics_yolo_train.py
New https://pypi.org/project/ultralytics/8.3.10 available 😃 Update with 'pip install -U ultralytics'
Ultralytics 8.3.7 🚀 Python-3.12.3 torch-2.4.1+cpu CPU (13th Gen Intel Core(TM) i5-13400)
engine\trainer: task=detect, mode=train, model=yolo11n.pt, data=coco128.yaml, epochs=100, time=None, patience=100, batch=7, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train40, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=False, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=C:\Users\fukag\PycharmProjects\UltralyticsTest\TestUltralyticsCuda\.venv\src\ultralytics\runs\detect\train40
...
Starting training for 100 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/100 0G 1.166 1.45 1.241 41 640: 100%|██████████| 19/19 [00:27<00:00, 1.44s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:08<00:00, 1.21it/s]
all 128 929 0.681 0.6 0.677 0.508
...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
100/100 0G 0.8943 0.75 1.037 7 640: 100%|██████████| 19/19 [00:23<00:00, 1.26s/it]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:07<00:00, 1.26it/s]
all 128 929 0.842 0.811 0.87 0.707
100 epochs completed in 0.911 hours.
...
4. WSL2 上で GPU を使用して training したときとの実行時間の比較
4.1. WSL2 上の Ubuntu に PyCharm をインストール
こちらのページから PyCharm Community Edition の Linux 版をダウンロードしました。
ダウンロード後、下記のコマンドで PyCharm を /opt/ ディレクトリに展開しました。
sudo tar xzf pycharm-*.tar.gz -C /opt/
私のユーザーアカウントの権限で PyCharm のバージョンアップができるよう、展開して生成されたディレクトリの権限を下記のコマンドで書き換えました。
sudo chown -R fukagai.fukagai /opt/pycharm-community-2024.2.2/
下記のコマンドで PyCharm の Linux 版が起動されます。Xサーバー等の設定はしておらず、WSLg を使用した GUI アプリとして起動しました。
/opt/pycharm-community-2024.2.2/bin/pycharm &
4.2. Ultralytics のインストール
PyCharm の Project をデフォルトの設定で作成後、PyCharm 下段のターミナルに下記のコマンドを入力しました。Ultralytics は editable mode でインストールしています。
下記のコマンドで、GPU を使用する設定で Ultralytics がインストールされました。
(.venv) fukagai@ESPRIMOWD2H2:~/PycharmProjects/TestUltralyticsCuda/.venv$ mkdir src (.venv) fukagai@ESPRIMOWD2H2:~/PycharmProjects/TestUltralyticsCuda/.venv$ cd src/ (.venv) fukagai@ESPRIMOWD2H2:~/PycharmProjects/TestUltralyticsCuda/.venv/src$ git clone https://github.com/ultralytics/ultralytics (.venv) fukagai@ESPRIMOWD2H2:~/PycharmProjects/TestUltralyticsCuda/.venv/src$ cd ultralytics/ (.venv) fukagai@ESPRIMOWD2H2:~/PycharmProjects/TestUltralyticsCuda/.venv/src/ultralytics$ pip install -e . Obtaining file:///home/fukagai/PycharmProjects/TestUltralyticsCuda/.venv/src/ultralytics Installing build dependencies ... done Checking if build backend supports build_editable ... done Getting requirements to build editable ... done Preparing editable metadata (pyproject.toml) ... done ... Successfully installed MarkupSafe-3.0.1 certifi-2024.8.30 charset-normalizer-3.4.0 contourpy-1.3.0 cycler-0.12.1 filelock-3.16.1 fonttools-4.54.1 fsspec-2024.9.0 idna-3.10 jinja2-3.1.4 kiwisolver-1.4.7 matplotlib-3.9.2 mpmath-1.3.0 networkx-3.4.1 numpy-2.1.2 nvidia-cublas-cu12-12.1.3.1 nvidia-cuda-cupti-cu12-12.1.105 nvidia-cuda-nvrtc-cu12-12.1.105 nvidia-cuda-runtime-cu12-12.1.105 nvidia-cudnn-cu12-9.1.0.70 nvidia-cufft-cu12-11.0.2.54 nvidia-curand-cu12-10.3.2.106 nvidia-cusolver-cu12-11.4.5.107 nvidia-cusparse-cu12-12.1.0.106 nvidia-nccl-cu12-2.20.5 nvidia-nvjitlink-cu12-12.6.77 nvidia-nvtx-cu12-12.1.105 opencv-python-4.10.0.84 packaging-24.1 pandas-2.2.3 pillow-10.4.0 psutil-6.0.0 py-cpuinfo-9.0.0 pyparsing-3.1.4 python-dateutil-2.9.0.post0 pytz-2024.2 pyyaml-6.0.2 requests-2.32.3 scipy-1.14.1 seaborn-0.13.2 six-1.16.0 sympy-1.13.3 torch-2.4.1 torchvision-0.19.1 tqdm-4.66.5 triton-3.0.0 typing-extensions-4.12.2 tzdata-2024.2 ultralytics-8.3.11 ultralytics-thop-2.0.9 urllib3-2.2.3
インストール後、Windows 版 PyCharm と同様、こちらのページの「3.4. Ultralytics のパスの追加」の手順で Git clone した Ultralytics のパスを Project の Interpreter Paths に追加しました。
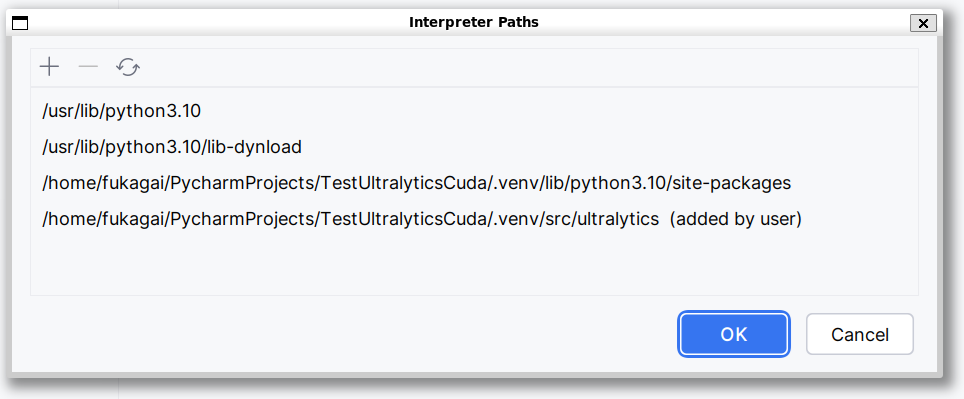
4.3. Ultralytics の training の実行
上記 2.4.4. と同様、batch=-1 を指定し、WSL2 の Ubuntu 上で Ultralytics の training を実行しました。
実行したのは上記 2.4.4. と同じ下記の Python スクリプトになります。
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="coco128.yaml", epochs=100, imgsz=640, batch=-1, amp=False, half=False)
下記のようなログが PyCharm のコンソールに出力され、0.168 時間で 100 epoch の training が完了しました。Windows 版で GPU を使用して実行したときの実行時間 0.162 時間と近い実行時間になりました。
/home/fukagai/PycharmProjects/TestUltralyticsCuda/.venv/bin/python /home/fukagai/PycharmProjects/TestUltralyticsCuda/.venv/src/test_ultralytics_train.py
...
Ultralytics 8.3.11 🚀 Python-3.10.12 torch-2.4.1+cu121 CUDA:0 (NVIDIA GeForce GTX 1650, 4096MiB)
engine/trainer: task=detect, mode=train, model=yolo11n.pt, data=coco128.yaml, epochs=100, time=None, patience=100, batch=-1, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=False, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=/home/fukagai/PycharmProjects/TestUltralyticsCuda/.venv/src/ultralytics/runs/detect/train
...
AutoBatch: Computing optimal batch size for imgsz=640 at 60.0% CUDA memory utilization.
AutoBatch: CUDA:0 (NVIDIA GeForce GTX 1650) 4.00G total, 0.04G reserved, 0.02G allocated, 3.94G free
...
Starting training for 100 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/100 2.23G 1.155 1.687 1.255 21 640: 100%|██████████| 19/19 [00:05<00:00, 3.38it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:02<00:00, 4.24it/s]
all 128 929 0.669 0.592 0.673 0.5
...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
100/100 2.17G 0.8802 0.744 1.02 15 640: 100%|██████████| 19/19 [00:04<00:00, 4.62it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:01<00:00, 6.70it/s]
all 128 929 0.818 0.828 0.875 0.713
100 epochs completed in 0.168 hours.
...